
신비한 외계 서판
DNA의, 마음을 사로잡는 다층 정보 시스템으로 탐구하기
Dominic Statham 글, 이종헌 역
출처: creation magazine Vol. 41(2019), No. 3 pp. 39-41

마이크로 소프트의 창립자 중의 한 사람인 빌 게이츠(Bill Gates)에 따르면, “DNA는 컴퓨터 프로그램과 같지만, 지금까지 만들어진 어떤 소프트웨어보다도 훨씬 더 앞서있다.”(1) 여기서 게이츠는 ‘게놈’을 언급하고 있는데, 그것은 DNA 속에 암호화된 지시의 집합으로써 배아의 성장과(사람 안에서 수정란으로부터 아기로의 성장을 지시하기 위해) 생물학적 세포의 일상적인 작용을 제어하는 데 사용되는 것이다.
독자로 하여금 DNA의 복잡함에 대한 단지 작은 통찰력을 얻도록 돕기 위해, 버려진 외계 우주선에서 발견한 전자 서판과 관련된 가상적인 이야기를 하고자 한다.(2) 여기에는 문서와 서적을 담은 도서관이 통째로 들어 있었다.
그 발견은 커다란 흥분을 자아냈고, 세계에서 최고의 언어학자들이 그 책에서 이상한 기호를 해독하려는 시도에 협력했다. 하나의 문서에는 우주선의 평면도와 엔진실에 관한 그림이 포함되어 있었고 많은 부분에 라벨이 붙어 있었다. 이것은 외계 언어를 이해하기 시작하는 데 필요한 결정적인 단서를 제공했다.
그 책을 연구하면 할수록 언어학자들은 더 많이 놀라게 되었다. 리뷰 모임에서 한 교수는 문장들을 히브리어에서처럼 오른쪽에서 왼쪽으로 읽어야한다고 보고했다. 다른 사람들은 의견을 달리하여 그것들을 영어에서처럼 왼쪽에서 오른쪽으로 읽어야한다고 말했다. 더 연구한 결과 그 둘 다 옳다고 나타났다. 팀 중 한 명이 우주선의 추진 시스템을 정비하기 위한 지침 설명서인 것으로 보이는 것을 연구했다. 그는 전형적으로, 동일한 세트의 문자(혹은 기호)를 왼쪽에서 오른쪽으로 읽어서 하나의 지침을 얻고, 다시 오른쪽에서 왼쪽으로 읽어서 또 다른 지침을 얻는다는 것을 발견했다. 즉, 각 문자열에는 두 가지 의미가 있는 것으로 보였다.
몇 주 후, 암호학의 전문가인 다른 교수가 연구실로 급히 들어왔는데, 그의 얼굴은 흥분으로 상기되어 있었다. 그는 동일한 지침 설명서의 일부분을 다른 언어를 사용하여 읽을 수 있다는 것을 발견했다. 그는 나중에 뉴스 기자에게 이야기의 전반부를 얻기 위해 영어로 읽기 시작하다가 이야기의 후반부를 얻기 위해 첫 페이지로 돌아가서 동일한 단어들을 프랑스어로 다시 읽기 시작해야 하는 책을 가지고 있는 것과 다소 비슷하다고 설명했다.
게다가, 하나의 언어에는 모든 단어가 단지 세개의 문자만을 가진다. 그러나 다른 문자로 시작하면, 다른 의미를 갖는 전혀 다른 문장을 얻게 된다. 한 절에서 기본 텍스트는 다음과 같다(3):

위치 1에서 시작하는 세 문자 단어를 구성해 보면 (위의 도표) 문장의 메시지는 연료 혼합물에 대한 사양으로 판명되었다. 위치 2에서 시작하는 단어를 구성해 보면 잠재적으로 손상을 주는 엔진 진동을 처리하기 위한 지침이었다. 위치 3에서 시작하는 단어를 구성하면 최적의 작동 온도에 도달하기 전에 엔진을 너무 빨리 작동하는 것에 대한 경고가 나왔다. 이 동일한 세트의 문자를 거꾸로 읽으면 엔진의 컴퓨터를 재부팅하는 데 필요한 정보가 제공된다.
프로젝트 책임자가 말한 바와 같이 놀라운 수준의 ‘데이터 압축’이 있었는데, 여기에는 짧은 문자열 안에 많은 정보가 채워져 있었다. 한 세트의 문자들은 읽은 방법에 따라 최대 12개의 다른 지침이 들어 있는 것으로 보인다.
6개월 후 또 다른 주목할 만한 발견이 있었다. 연구자들 중 한 명이 연구할 조용한 장소가 필요하여 서판을 우주선의 주방으로 보이는 곳으로 가져갔다. 문서를 열었을 때, 그녀는 문자 중 일부가 ‘회색으로 변하며’ 거의 보이지 않는다는 사실을 알게 되었다:

검은 색 문자들만 읽었을 때, 그녀는 점심 메뉴 항목에 대한 조리법을 발견했다. 그 문서는 ‘문맥에 의존하는’ 것으로 보이는데, 즉 특정한 장소에서 특별한 작업을 수행하는 데 필요한 정보를 제공하기 위해 스스로 변환되는 것으로 보인다. 이것은 연구원이 서판을 항해실로 보이는 곳으로 가져갔을 때 확인되었다. 즉시 본문이 변경되어 다른 문자들이 회색으로 표시되었다. 그 결과 읽을 수 있는 본문은 먼 태양계를 통과하는 항로를 플롯하기 위한 절차의 일부라는 것이 나중에 발견되었다.
Information systems in biological cells(생물 세포 안의 정보 체계)
우리의 이야기는 독자들에게 환상적으로 보일지 모르겠지만 실제 세계에서 그에 필적하는 것이 있는데, 인간 게놈이 이와 같다.(4) DNA는 앞으로도 뒤로도 읽을 수 있으며, 종종 다른 지침이 중첩되며 심지어 순서가 역전되기도 한다. 외계 언어와 마찬가지로, 게놈의 여러 곳에서 서로 다른 문자로 시작하는 것에 따라 서로 다른 ‘문장’이 형성된다. 게다가 외계인의 서판에서 나타난 본문이 어느 방에 있느냐에 따라 자동적으로 변환되는 것처럼, 유전자(DNA 명령)가 자동으로 켜지거나 꺼져서 식물과 동물이 변화하거나 다른 방식으로 작동하게 하여 그들이 다른 환경에 적응하도록 한다.
그보다 더, 인간의 유전자는 ‘인트론(비구조부위)’과 ‘엑손’으로 알려진 섹션으로 나뉘어지는 DNA ‘문자’의 세트로 구성된다. DNA가 복사된 후에, 인트론은 제거되어야하고 나머지 엑손은 함께 연결되어야 한다(그림 1을 보라). 서로 다른 엑손은 서로 다른 방법으로 결합되어 여러 가지 지침을 만들어 낸다. 이것들은 차례로 서로 다른 시간에 서로 다른 단백질을 만드는 데에 사용되며, 그렇게 해서 만들어진 단백질은 세포의 유형마다 다르다. 사실상, 인간 게놈은 주위에 있는 엑손을 매우 복잡한 방식으로 교환함으로써, DNA를 ‘잘라내고 붙여넣는’ 거대한 ‘스플라이싱과 다이싱(spicing and dicing)’ 체계를 가지고 있다.(5) 하나의 엑손은 많은 다른 유전자에 포함될 수 있는데, 그 중의 일부 코드는 유사성이 거의 없는 단백질 형태를 특정하는 것이다. 초파리(Drosophila)에서 동일한 ‘유전자’가 수천 개의 서로 다른 단백질을 특정하는 데에 사용될 수 있다.(6)(역주, 스플라이싱: 단백질을 암호화하고 있지 않은 인트론(intron) 부위를 제거하고 단백질로 번역되는 부분인 엑손(exon)끼리 연결시켜주는 과정)
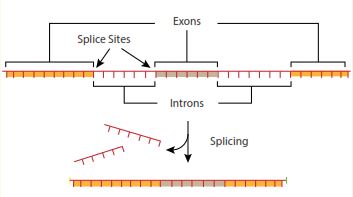
그림 1. 단백질을 만들기 위해서는 단백질 언어로 ‘번역되기’ 전에 먼저 DNA를 복사해야 한다. 그러나 번역을 하기 전에 인트론을 제거해야 한다. 나머지 엑손은 여러 가지 방법으로 서로 결합되어 서로 다른 지시를 만들어 내고 그렇게 함으로써 서로 다른 단백질을 위한 코딩(유전 암호 지정)을 할 수 있다.
또한 동일한 세트의 글자들은 그것을 읽는 데에 사용된 ‘언어’에 따라 다른 의미를 가질 수 있다. DNA의 한 섹션은 단백질의 형태, 인트론-엑손 결합(splice) 위치(그림 1) 및 히스톤 결합(binding) 위치(그림 2를 보라) 등을 위한(즉, 그것들을 위한 지시를 제공하기 위한) 코딩을 동시에 할 수 있다. 이들 모두는 정보를 ‘읽고’ 그에 따른 행동을 하기 위해 서로 다른 생물학적 나노 머신을 필요로 한다.
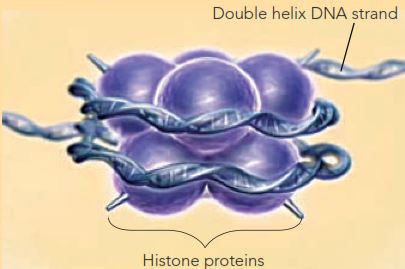
그림 2. (예를 들어 박테리아가 아닌) 보다 복잡한 생물체에서는 DNA가 히스톤(histone)이라고 불리는 단백질로 둘러싸여 있다. 둘러싸는 과정을 제어함으로써 필요에 따라 유전자를 켜고 끌 수 있다. DNA의 일부 돌출(stretches)에는 DNA가 히스톤에 결합하는 방법과 위치, 따라서 유전자가 사용되는 시기와 방법을 특정하는 정보를 포함한다. 따라서 ‘유전자’는 단백질을 만드는 방법을 특정하는 정보와, 동시에 단백질을 만들어 내는 시기를 통제하는 정보를 담고 있다. 이것은 두 가지 의미를 갖는 문장을 갖고 있는 것과 같다.
우리의 외계 언어 유사(analogy)는 DNA 언어의 놀라운 복잡성을 희미하게 반영한 것일 뿐이며, 세포 내의 정보 시스템은 실제로 이것보다 훨씬 더 정교하다. 예를 들어, DNA는 세포 내에서 정보를 운반하는 유일한 분자는 아니다. 장쇄 당(long-chain sugars)(7)과 같은 다른 분자는 단백질을 변형시키는 데 사용된다. 세포막 패턴과 심지어 막 분자에 의해 생성된 전기장 또한 중요한 정보를 전달한다. 이 모든 것들은 배아가 성장하는 방법과 성인 신체가 기능 하는 방법을 제어한다.
진화론자들은 이런 수준의 복잡성과 정교함을 지닌 정보 시스템을 원격으로 만들어 낼 수 있는 것으로 보이는 자연의 과정을 결코 지적하지 못했다. 오히려, 그들은 단순히 그러한 과정이 존재한다는 것을 믿음으로 믿는다. 특히, 다윈주의자들은 여러 가지 다른 방식으로 기능하는 DNA 서열을 설명하기가 매우 어렵다. 무작위 돌연변이가 한 방향으로 읽을 때 서열의 개선을 가져온다 할지라도 그 서열을 다른 방법으로 읽을 때 그것은 거의 예외 없이 항상 정보를 저하시킨다.
생물 세계의 아름다움과 복잡함을 바라볼 때 우리는 시편 139편 14절에서 다윗왕이 하나님께 한 말씀을 되뇌어야 한다: “내가 주께 감사하옴은 나를 지으심이 심히 기묘하심이라.”
References and notes
1. Gates, B., The Road Ahead, Penguin Group, New York, p. 188, 1995.
2. Of course, CMI rejects the idea of aliens—see our documentary Alien Intrusion: Unmasking the Deception, available at creation.com/s/30-9-566.//물론 CMI는 외계인에 대한 개념을 거부한다. ‘외계인의 침입’에 관한 우리의 기사를 보라: ‘속임수를 폭로하기’, creation.com/s/30-9-566 참조.
3. The symbols used in this illustration are an old Persian cuneiform script, here randomly arranged.//이 설명에서 사용한 기호는 고대 페르시아의 설형문자이며, 여기서는 임의적으로 배열했다.
4. Sanford, J., Genetic Entropy and the Mystery of the Genome, Ivan Press, New York, pp. 131–133, 2005.
5. Carter, R., Splicing and dicing the human genome; creation.com/splicing, 29 Jun 2010.
6. Zinn, K., Dscam and neuronal uniqueness, Cell 129(3):455-6, 4 May 2007; cell.com.
7. While DNA and RNA sequences are one-dimensional, sugar molecules are three-dimensional, and therefore potentially carry even more information. See Wells, J., Membrane patterns carry ontogenetic information that is specified independently of DNA, BIO-Complexity 2:1–28, 2014; bio-complexity.org. See also, ID inquiry: Jonathan Wells on codes in biology, Interview, Discovery Institute, 2015; discovery.org.
DOMINIC STATHAM, B.Sc., D.I.S., M.I.E.T., C.Eng.
spent 25 years working as an engineer in the aeronautical and automotive industries. He is now a speaker/writer for CMI-UK/Europe. For more: creation.com/statham.
 화석이 하루만에? - Ron Neller 글, 이종헌 역
화석이 하루만에? - Ron Neller 글, 이종헌 역
 티라노사우루스가 상어와 함께 걸었다? - Gavin Cox 글, 이종헌 역
티라노사우루스가 상어와 함께 걸었다? - Gavin Cox 글, 이종헌 역